Lately, I’ve taken a break from my Ansible work to concentrate on WorkFlow Automation by NetApp. I know, I know, why am I working with yet another automation project. I’ve discussed previously here and here how Ansible fits into provisioning and managing NetApp storage; however, there are times when WFA is the appropriate tool. This isn’t an introduction to WFA. If that’s what you’re looking for then I suggest you start with this excellent post from @triggan. This is meant to provide some tips on writing workflows and some gotchas that I’ve run across while working with WFA.

One of the benefits of using WFA is its integration with Powershell. This should be very comforting to those Microsoft fanboys out there. That being said, there are some sticking points I want to bring to light. First let’s provide some context. I recently had a customer who wanted to migrate some very intricate shell scripts into WFA. They previously had all their arrays hard coded into the scripts. This is a quick and dirty fix that we’ve all done but if there is a programmatic way to pull that information from a live data source then we’re appeasing the design pattern gods. Enter the WFA database. WFA becomes your current source of record because it periodically pulls data from OnCommand Unified Manager which you should be using to monitor your NetApp environment. Shame on you if you’re not. Instead of hard coding array names into your script, you are only a SQL query away from all current clusters in your environment. Below is an example query with the results.
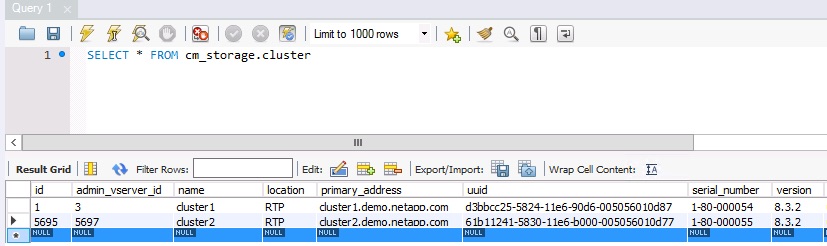
Excellent, I have a way to programmatically pull all clusters in my environment and I can perform some sort of task against them. In my case, I only needed the cluster names so I changed my query to the following.
SELECT cluster.name FROM cm_storage.cluster
Now that I have a list of my clusters I should be able to send that to my next cmdlet via the Powershell pipeline, right?
Wrong
Another benefit of using WFA for your NetApp environment is that it natively provides a repository for credentials. Instead of hard coding usernames and passwords into your scripts, you can utilize the Connect-WfaCluster cmdlet and WFA will connect using the internal credential store. So how come the following is falling over?
$clusters = @(Invoke-MySqlQuery -Query "SELECT cluster.name FROM cm_storage.cluster")
$clusters | Connect-WfaCluster
After taking a peek at the full help for the Connect-WfaCluster cmdlet I discover that the “-Node” parameter doesn’t accept pipeline input. Ok, if it doesn’t take pipeline input then I’ll use a for-loop to iterate through my clusters. That will definitely work.
Wrong again
ForEach-Object ($clust in $clusters) {
Connect-WfaCluster $clust
}
After banging my head a few times and some google-fu, I came across an article that explains the difference between ForEach-Object and ForEach. If you’re too lazy to read the article the gist of it is that ForEach-Object utilizes the pipeline while the ForEach statement loads the array into memory and processes it from there. That pretty much forces my hand. I ended up using the following to successfully connect to all my clusters and execute workflows against them.
$clusters = @(Invoke-MySqlQuery -Query "SELECT cluster.name FROM cm_storage.cluster")
foreach ($clust in $clusters.name) {
Connect-WfaCluster $clust
...
}
Dance with the girl that brung ya.
I don’t know if I would have run into this problem had I chosen to implement the WFA script in PERL. I’m guessing not but I’m open to suggestions from any of you PERL gurus out there. I thought I had a pretty firm grasp on Powershell before I started this adventure but I’m starting to find out just how much I don’t know the more I proceed. Such is life.